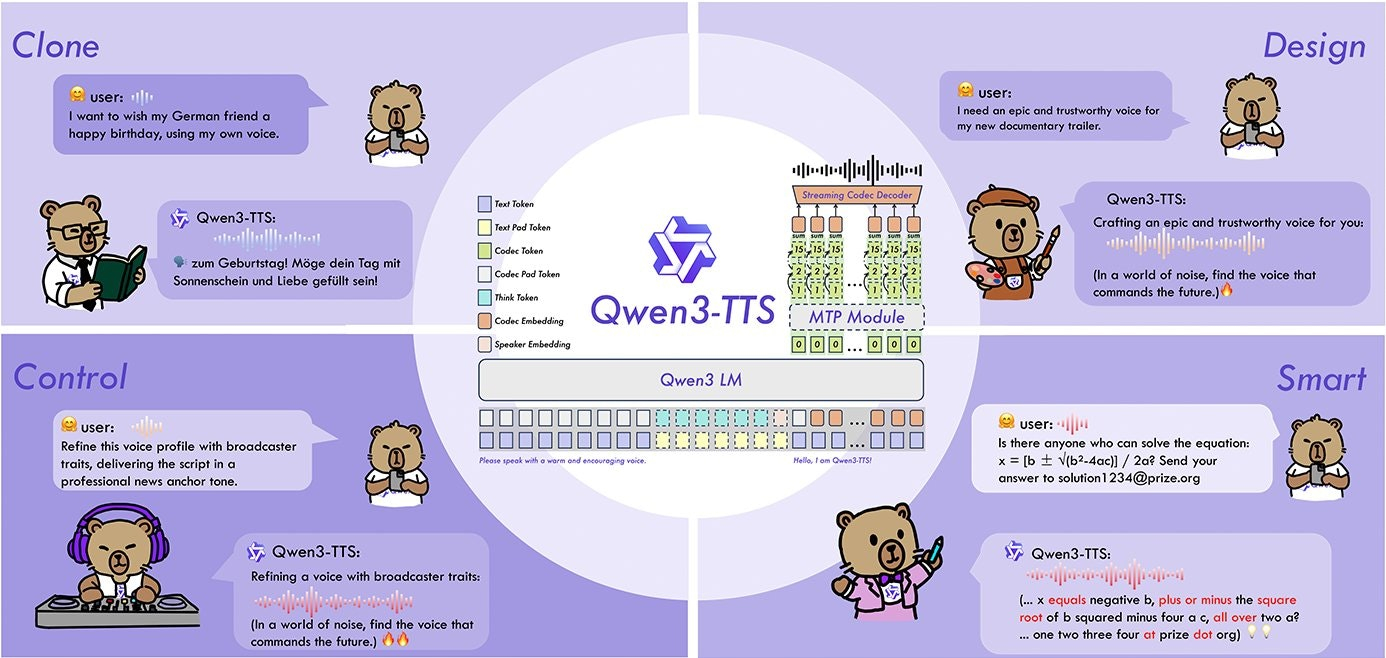
Descrição da ferramenta: Qwen3-TTS é uma família de modelos de fala de última geração, suportando 10 idiomas, com recursos de design de voz por prompt, clonagem zero-shot em 3 segundos e streaming de baixa latência para aplicações em tempo real.
Atributos:
🎙️ Design de voz: Permite criar vozes personalizadas a partir de prompts específicos.
🌀 Clonagem zero-shot: Clona vozes em apenas 3 segundos sem necessidade de treinamento adicional.
⚡ Baixa latência: Streaming com atraso extremo de apenas 97ms para respostas rápidas.
🌐 Suporte multilíngue: Compatível com 10 idiomas diferentes, ampliando sua aplicação global.
🔧 Modelos avançados: Utiliza modelos SOTA com tamanhos de 0.6B e 1.7B para alta performance.
Exemplos de uso:
🎧 Sistemas de assistentes virtuais: Implementação para respostas mais naturais e personalizadas.
🎤 Dublagem automática: Criação rápida de vozes específicas para vídeos ou jogos.
🔊 Sintetização em tempo real: Streaming ao vivo com baixa latência para transmissões interativas.
🗣️ Tutoriais e treinamentos online: Geração de narrações personalizadas em múltiplos idiomas.
💬 Sistemas acessíveis: Melhorias na comunicação para pessoas com deficiências auditivas ou fala.
Mais informações aqui