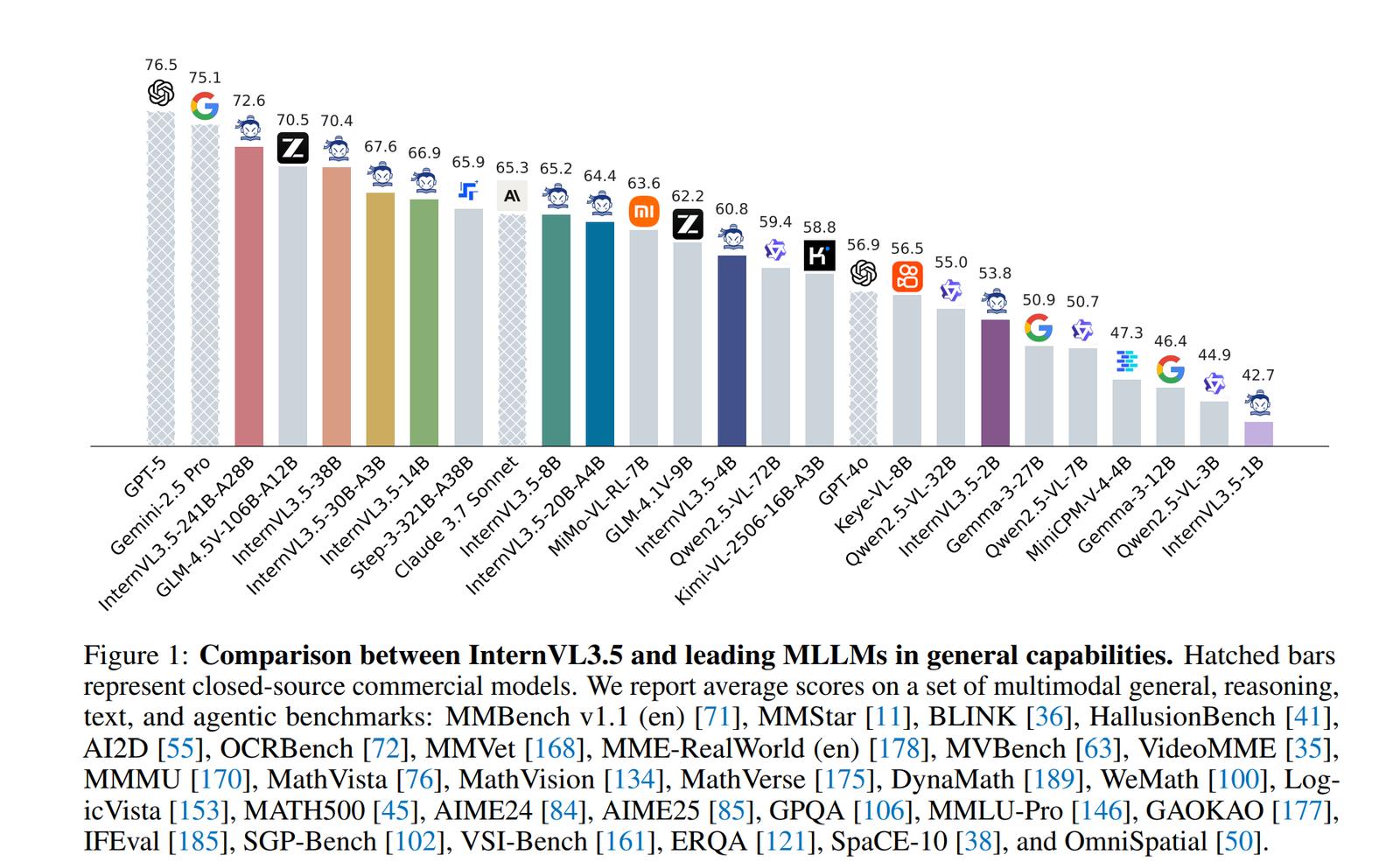
Descrição da ferramenta: InternVL3.5 é uma família de modelos multimodais de código aberto, com capacidades avançadas de raciocínio e desempenho de ponta, oferecendo maior velocidade de inferência em comparação com versões anteriores.
Atributos:
🧠 Capacidade de raciocínio: Realiza tarefas complexas de lógica e análise com alta precisão.
⚡ Velocidade de inferência: Opera até 4 vezes mais rápido que versões anteriores, otimizando o processamento.
🔄 Aprendizado por Cascade Reinforcement: Utiliza uma técnica avançada para aprimorar o desempenho do modelo.
🌐 Multimodalidade: Integra diferentes tipos de dados, como texto e imagens, para análises mais completas.
💻 Código aberto: Disponível para a comunidade, promovendo colaboração e customização.
Exemplos de uso:
🤖 Sistemas de suporte à decisão: Auxilia na análise complexa de dados multimodais para tomada de decisão empresarial.
📝 Análise automatizada de documentos: Interpreta textos e imagens em processos jurídicos ou administrativos.
🎮 Painéis interativos em jogos: Implementa agentes inteligentes capazes de raciocínio avançado em ambientes virtuais.
📊 Análise visual e textual integrada: Combina informações visuais e textuais para relatórios detalhados.
🚀 Pesquisas acadêmicas: Facilita estudos que envolvem múltiplas modalidades de dados com alta precisão analítica.


