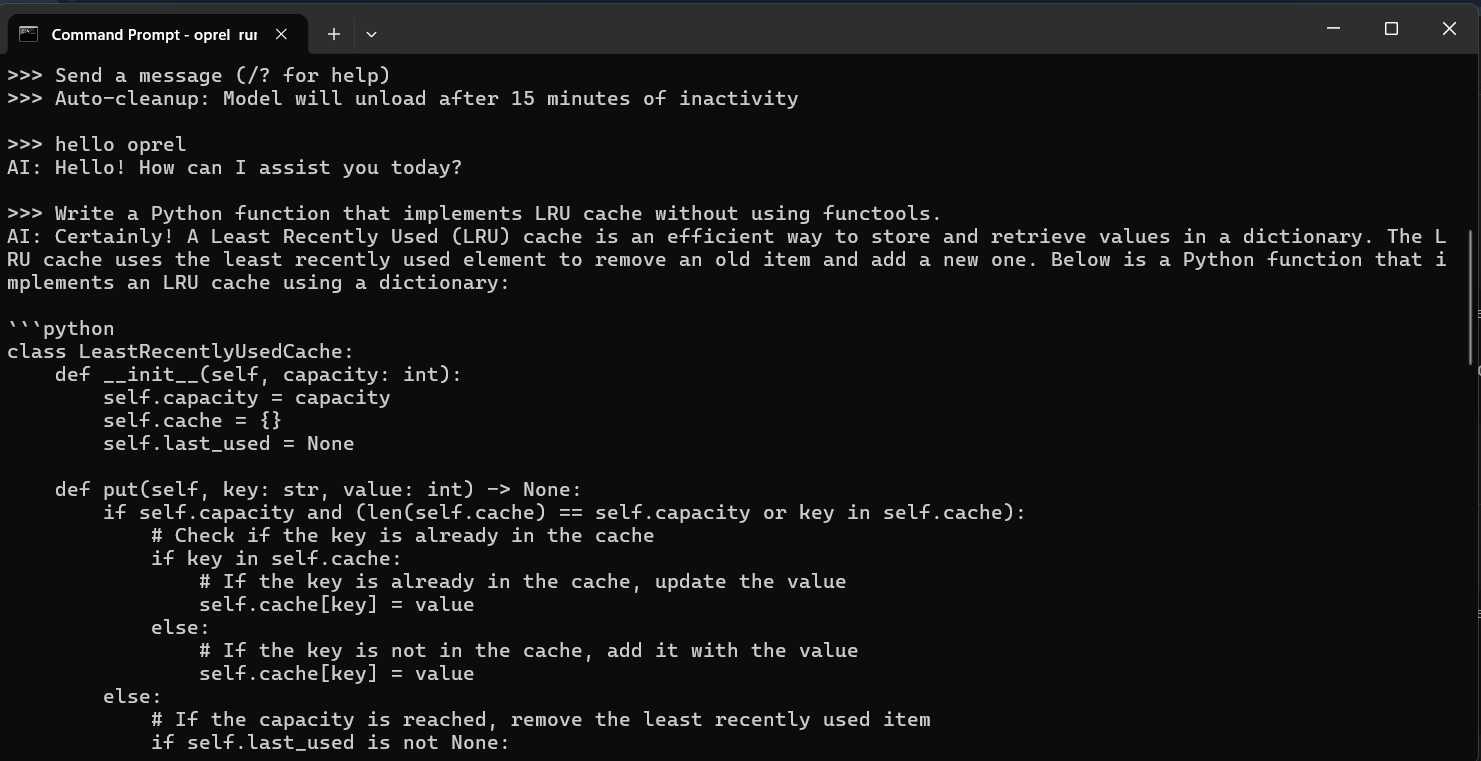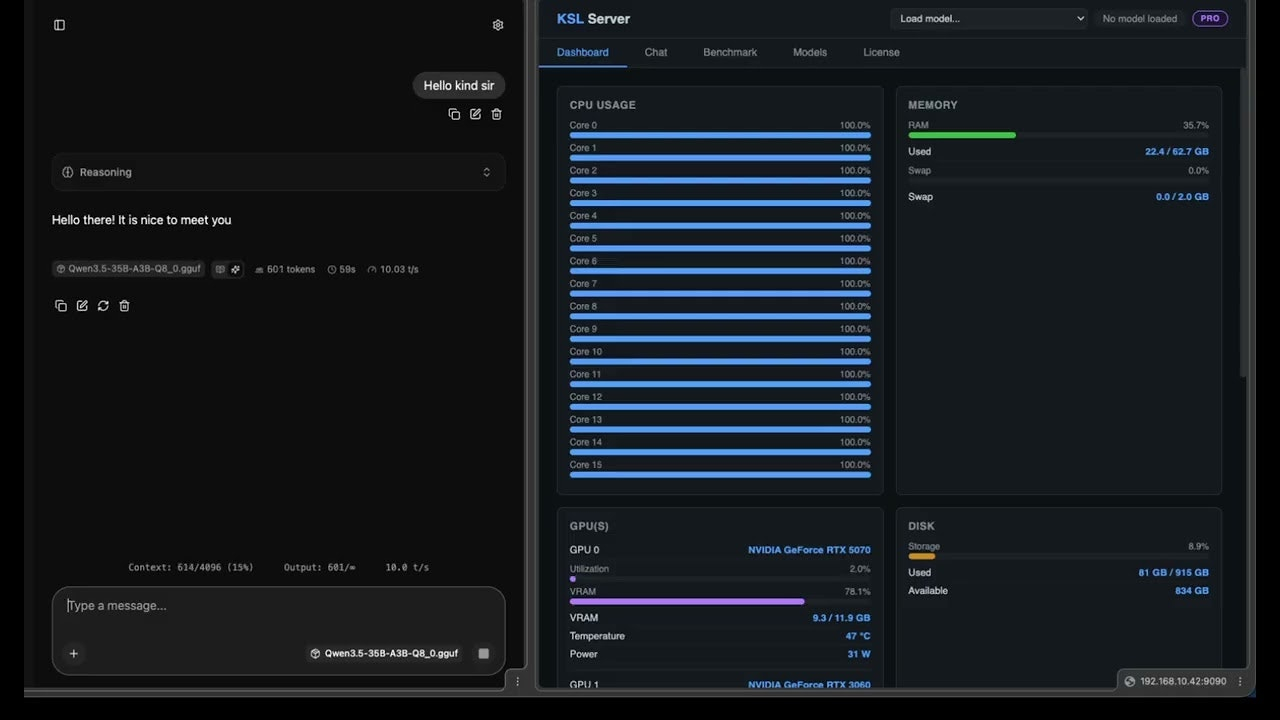
Descrição da ferramenta: Baldur KSL é um motor de inferência de alto desempenho para modelos de linguagem AI, otimizando a execução de modelos Mixture-of-Experts em GPUs NVIDIA, proporcionando velocidade e privacidade ao usuário.
Atributos:
🛠️ Otimização Proprietária: Tecnologia exclusiva que acelera significativamente a execução de modelos AI em hardware local.
⚡ Alta Performance: Permite rodar modelos complexos até 185% mais rápido do que métodos tradicionais.
🔒 Privacidade: Executa modelos localmente, eliminando a necessidade de APIs na nuvem e preservando dados sensíveis.
💻 Compatibilidade com GPUs NVIDIA: Funciona eficientemente em hardware comum, sem necessidade de infraestrutura especializada.
🚀 Escalabilidade: Suporta grandes modelos como o IA 35B, facilitando aplicações avançadas.
Exemplos de uso:
📝 Aceleração de chatbots internos: Executa rapidamente grandes modelos para respostas instantâneas sem depender da nuvem.
🔍 Análise de textos confidenciais: Processa dados sensíveis localmente, garantindo privacidade e segurança.
🎯 Pilotos automotivos: Utiliza modelos avançados para interpretação rápida de comandos e sensores veiculares.
📊 Análise preditiva empresarial: Implementa inferências rápidas em sistemas internos para tomada de decisão ágil.
🎮 Jogos com IA personalizada: Executa modelos complexos para experiências interativas em dispositivos locais.