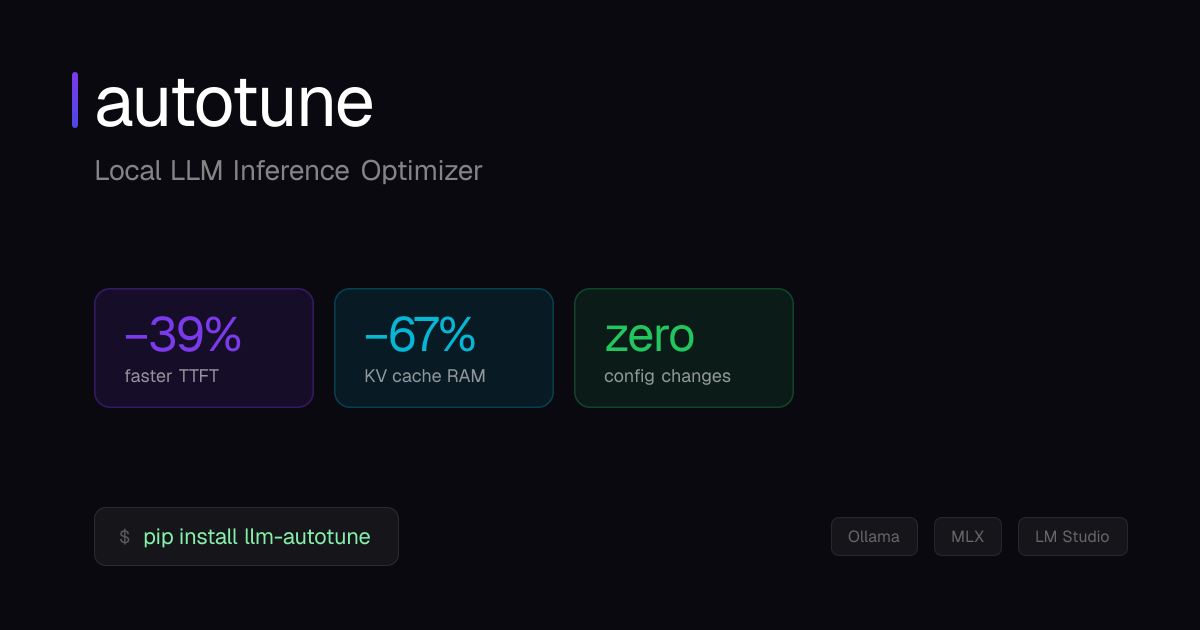
Descrição da ferramenta: Autotune é um otimizador de runtime de código aberto para LLMs locais, que reduz o uso de memória KV cache, melhora a latência do primeiro token e ajusta dinamicamente as configurações de inferência conforme o hardware e a carga de trabalho.
Atributos:
🛠️ Otimização de desempenho: Ajusta automaticamente configurações para maximizar a eficiência na execução dos modelos.
💾 Gerenciamento de memória: Reduz significativamente o uso de memória KV cache durante a operação.
⚡ Redução da latência: Diminui o tempo até o primeiro token ser gerado, acelerando respostas.
🔧 Compatibilidade: Funciona com Ollama, MLX e via API, integrando-se facilmente ao fluxo existente.
🤖 Ajuste dinâmico: Adapta-se às especificidades do hardware e workload em tempo real.
Exemplos de uso:
📝 Implementação em chatbots locais: Melhora a velocidade e eficiência na resposta de assistentes virtuais hospedados localmente.
📊 Análise de desempenho: Benchmarking para avaliar melhorias no tempo de inferência e uso de memória após otimizações.
⚙️ Ajuste automático em ambientes heterogêneos: Configura automaticamente os parâmetros para diferentes hardwares sem intervenção manual.
🔍 Tuning para workflows específicos: Personaliza configurações para tarefas como geração de texto ou classificação em cargas variáveis.
🚀 Integração com APIs existentes: Facilita a implementação em sistemas que utilizam APIs compatíveis com OpenAI, otimizando sua performance.
