Descrição da ferramenta:
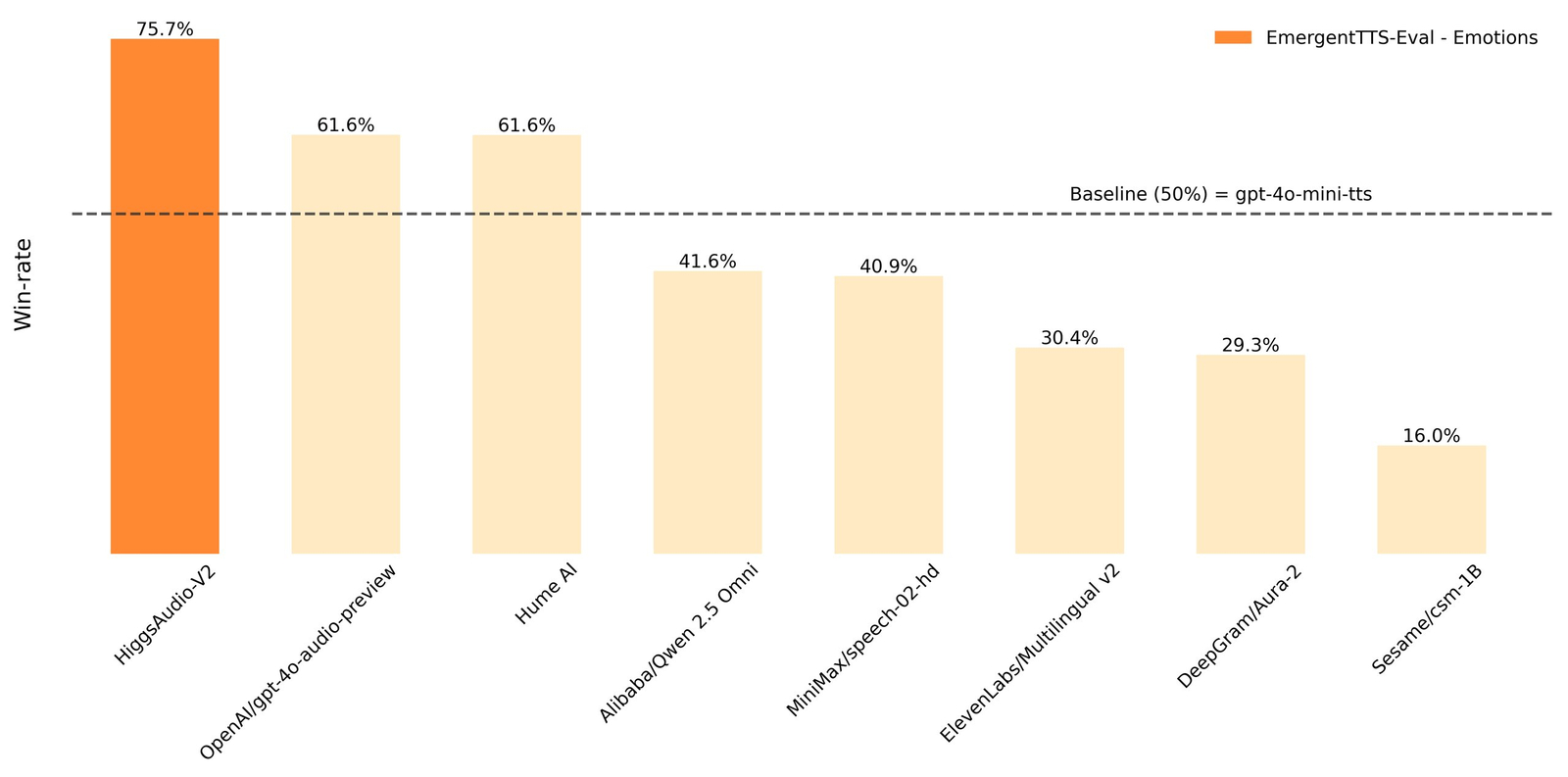
O VARCO Sound permite criar, personalizar e ajustar sons de forma rápida e intuitiva, atendendo às necessidades específicas de projetos audiovisuais, jogos ou aplicações profissionais com alta precisão sonora.
Atributos:
🎚️ Controle de tonalidade: Permite ajustar a frequência e o tom do som para obter o efeito desejado.
🎛️ Personalização: Oferece recursos para modificar características sonoras conforme a preferência do usuário.
⚙️ Facilidade de uso: Interface intuitiva que simplifica o processo de criação e edição de áudio.
🔄 Reprodução instantânea: Gera resultados em tempo real, facilitando ajustes rápidos.
💾 Salvamento de configurações: Possibilidade de salvar perfis personalizados para uso futuro.
Exemplos de uso:
🎧 Criar efeitos sonoros para jogos: Desenvolver sons específicos para ambientes ou personagens em jogos digitais.
🎼 Produção musical personalizada: Gerar sons únicos para composições ou trilhas sonoras.
🔊 Ajuste de áudio para vídeos profissionais: Refinar efeitos sonoros em produções audiovisuais.
🛠️ Sons para aplicativos interativos: Criar áudios que respondem às ações do usuário em plataformas digitais.
📢 Sons ambientais sob medida: Produzir ambientes sonoros específicos para cenários virtuais ou experiências imersivas.