Descrição da ferramenta:
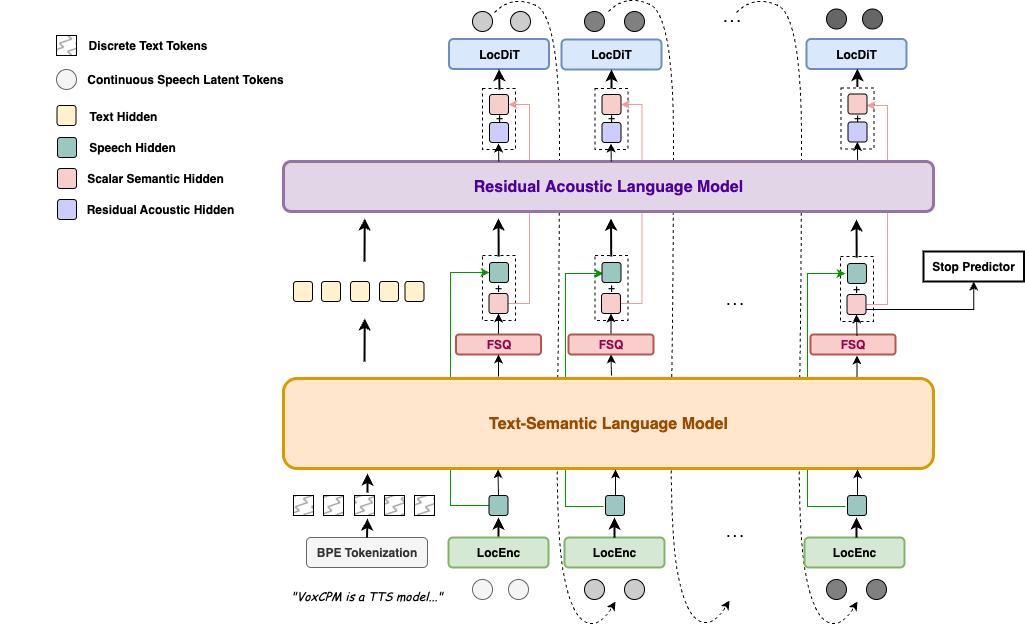
O IndexTTS2 é uma solução de texto para fala pronta para produção, que oferece controle preciso de duração, clonagem emocional e separação entre falantes, ideal para dublagem, jogos, podcasts e educação.
Atributos:
🎯 Controle de Duração: Permite ajustar com precisão a duração do áudio gerado.
🎭 Emoção–Speaker Decoupling: Separa emoções do perfil do locutor para maior flexibilidade na expressão.
🧬 Zeroshot Cloning: Clona vozes específicas sem necessidade de treinamento prévio.
⚙️ Produção Pronta: Ferramenta otimizada para uso em ambientes profissionais e de produção.
🔄 Versatilidade de Aplicações: Adequada para dublagem, jogos, podcasts e conteúdos educacionais.
Exemplos de uso:
🎙️ Dublagem de filmes: Criação de vozes com controle preciso de duração e emoção específica.
🕹️ Dublagem em jogos: Geração rápida de diálogos com diferentes emoções e estilos vocais.
🎧 Podcasts automatizados: Produção de episódios com vozes personalizadas e ajustadas ao tom desejado.
📚 E-learning: Narração de conteúdos educativos com variações emocionais controladas.
🤖 Sistemas interativos: Implementação em assistentes virtuais que requerem respostas naturais e expressivas.