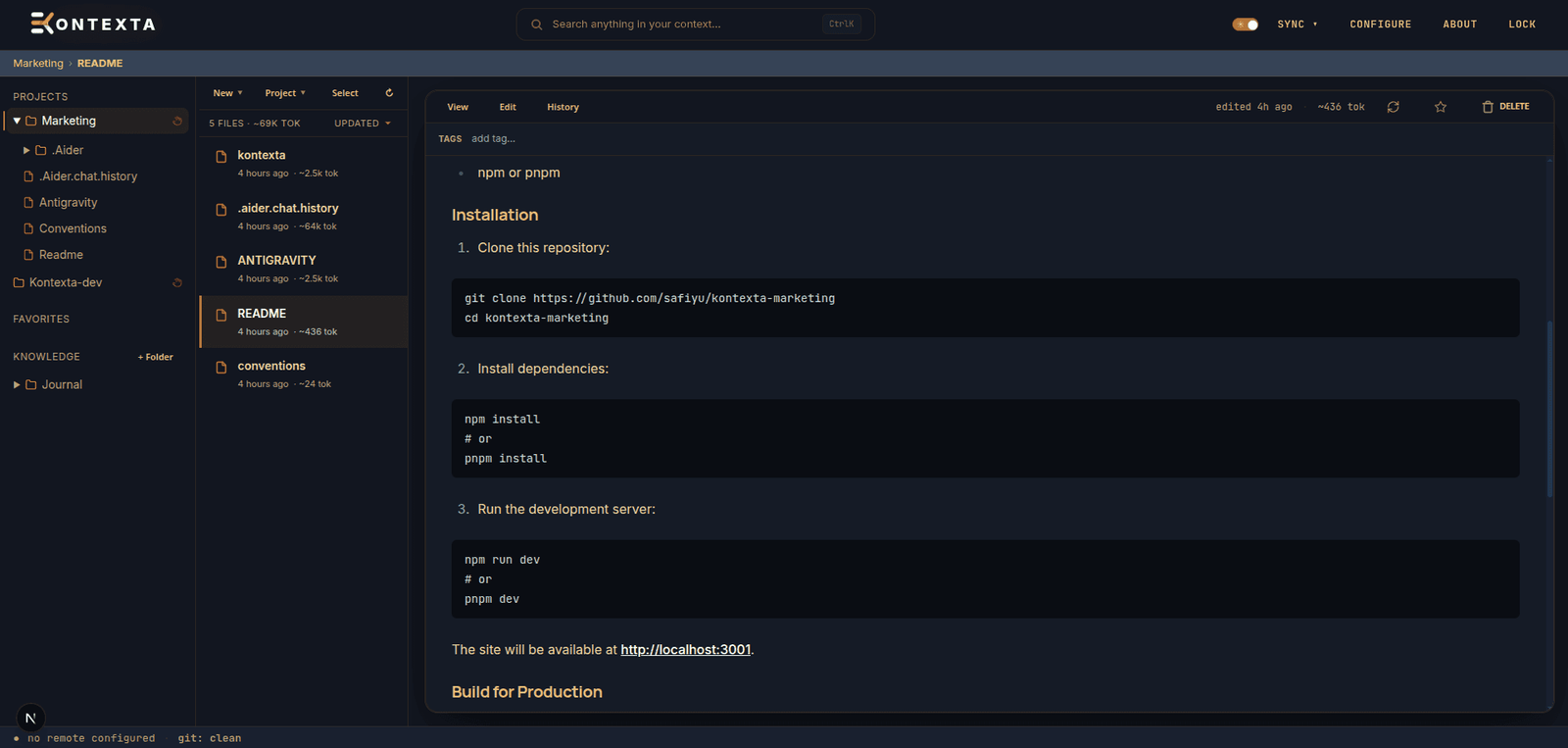
Descrição da ferramenta: Kontexa é uma plataforma que oferece gerenciamento de contexto persistente, execução controlada e continuidade entre agentes, priorizando privacidade e economia de recursos, sem necessidade de assinaturas em nuvem.
Atributos:
🧠 Contexto Persistente: Mantém informações relevantes ao longo do tempo para melhorar a continuidade das operações.
🔒 Privacidade Local: Funciona totalmente offline, garantindo segurança e confidencialidade dos dados.
💰 Economia de Tokens: Reduz custos ao otimizar o uso de APIs externas e gerenciar eficientemente o contexto.
⚙️ Execução Controlada: Permite comandos seguros e precisos, evitando ações indesejadas ou inseguras.
🌐 Handoff entre Agentes: Facilita a transferência de tarefas entre diferentes agentes com continuidade preservada.
Exemplos de uso:
💻 Sistema Local de IA: Implementar um servidor local para processamento privado sem dependência da nuvem.
📝 Edição Segura de Documentos: Manter o contexto durante sessões de edição colaborativa com privacidade garantida.
💡 Soluções Empresariais: Gerenciar múltiplos agentes para automação interna sem expor dados sensíveis na nuvem.
🔍 Análise Contextual Offline: Realizar análises detalhadas usando memória local, evitando custos com APIs externas.
🤝 Handoff entre Agentes: Transferir tarefas complexas entre diferentes sistemas ou agentes mantendo o contexto intacto.
Mais informações aqui.