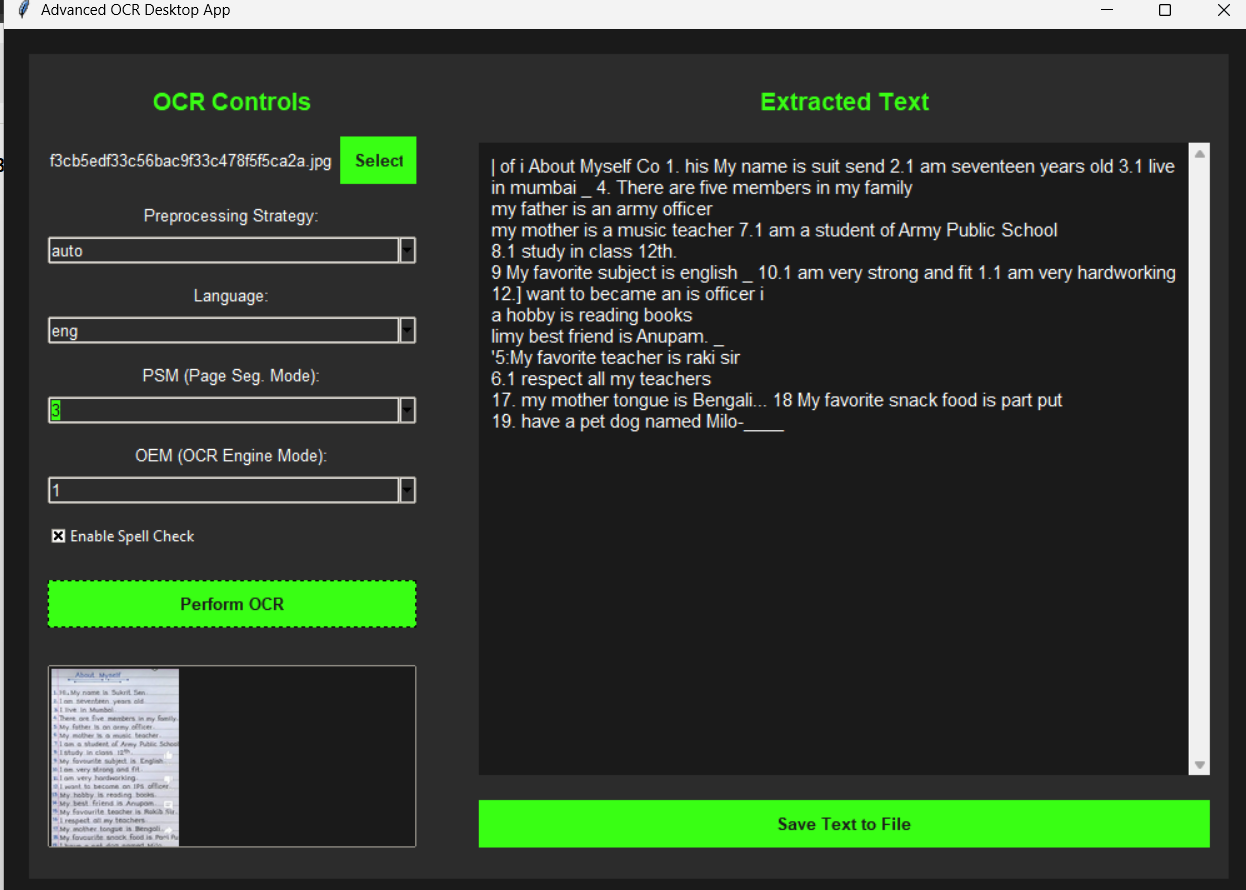
Descrição da ferramenta: OCR Tool é uma aplicação Python que utiliza Tesseract OCR para extrair texto de imagens e PDFs digitalizados, oferecendo opções de saída em formatos TXT ou CSV, com suporte a limpeza básica de imagens via OpenCV.
Atributos:
📝 Precisão: Capacidade de reconhecer e extrair textos com alta fidelidade a partir de imagens e PDFs digitalizados.
⚙️ Facilidade de uso: Interface simples que permite operações rápidas sem necessidade de configurações complexas.
🖼️ Suporte a múltiplos formatos: Compatível com arquivos JPG, PNG e PDFs digitalizados para extração de texto.
🧹 Pré-processamento: Inclui funcionalidades básicas de limpeza de imagem usando OpenCV para melhorar a precisão do OCR.
📂 Opções de exportação: Permite salvar o texto extraído em formatos TXT ou CSV, facilitando análises posteriores.
Exemplos de uso:
🔍 Análise de documentos escaneados: Extração rápida de textos contidos em PDFs digitalizados para processamento automatizado.
🖼️ Reconhecimento em imagens isoladas: Captura do conteúdo textual presente em fotos ou capturas de tela para armazenamento ou edição.
📝 Edição e revisão textual: Obtenção do texto extraído para correções ou revisões manuais em editores externos.
📊 Análise de dados estruturados: Exportação do conteúdo em CSV para análise estatística ou integração com bancos de dados.
🔧 Ajuste pré-processamento: Utilização das funções básicas do OpenCV para melhorar a qualidade da imagem antes da extração.