Descrição da ferramenta:
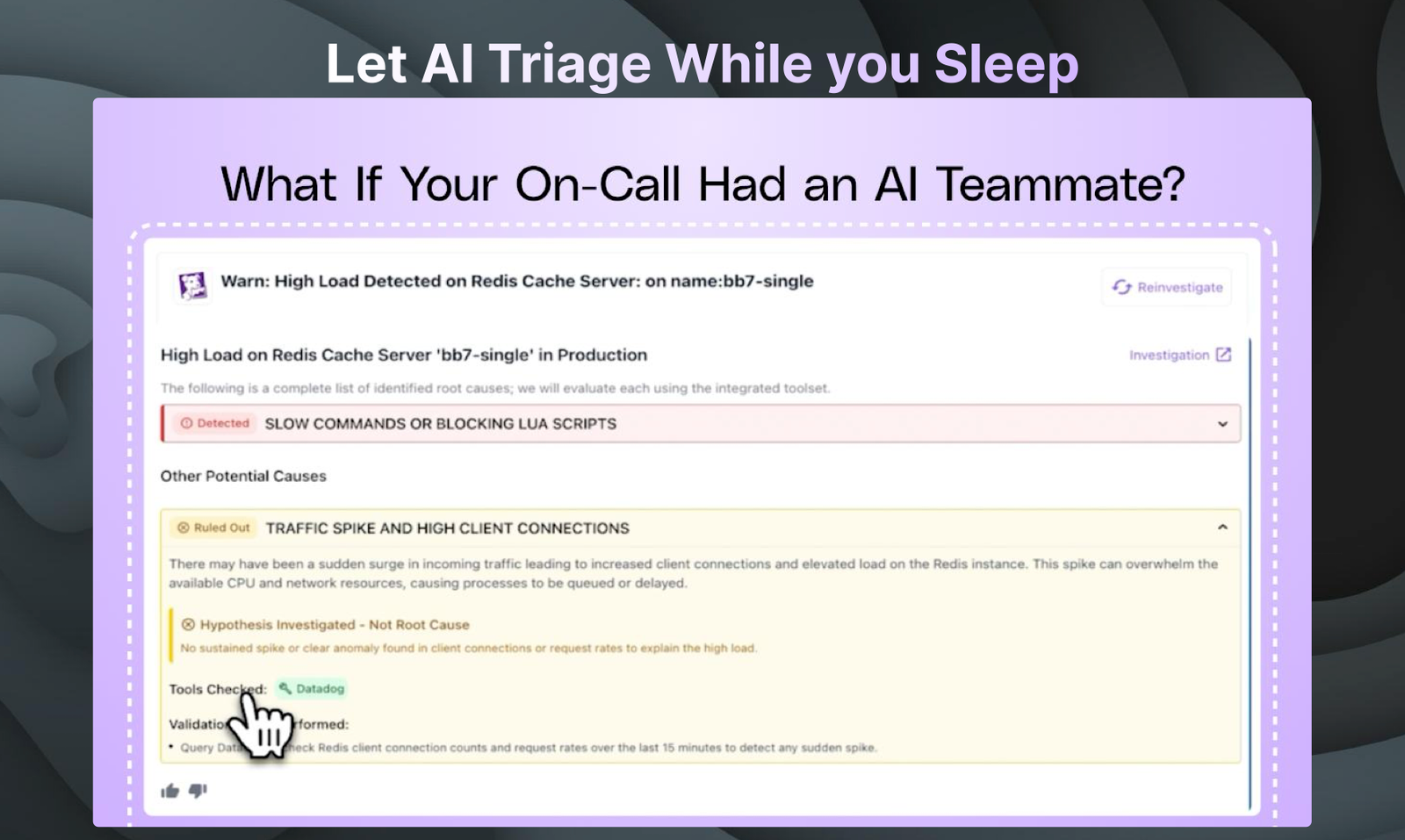
DrDroid é um agente de IA que automatiza triagem, diagnóstico e resolução de incidentes de produção, integrando-se a mais de 50 ferramentas para acelerar a resolução de problemas e otimizar o tempo dos engenheiros.
Atributos:
🛠️ Integração Ampla: Compatível com mais de 50 ferramentas, incluindo Datadog, Grafana, Kubernetes e provedores de nuvem.
🤖 Automação Inteligente: Automatiza tarefas de triagem, troubleshooting e remediação para reduzir o esforço manual.
⏱️ Eficiência Temporal: Ajuda engenheiros a economizar horas semanais ao resolver incidentes rapidamente.
🔧 Resolução Rápida: Facilita uma resposta ágil às falhas em ambientes de produção.
📊 Análise Integrada: Fornece insights detalhados sobre incidentes e seu contexto para ações informadas.
Exemplos de uso:
📝 Análise Automática de Incidentes: Diagnóstico automático ao detectar uma falha no sistema.
🚑 Remediação Imediata: Execução automática de ações corretivas após identificação do problema.
🔍 Troubleshooting Assistido: Auxílio na investigação detalhada de eventos anormais usando integrações com ferramentas como Grafana ou Datadog.
📈 Acompanhamento em Tempo Real: Monitoramento contínuo do status do sistema durante incidentes críticos.
⚙️ Ajuste de Configurações Automatizado: Alterações automáticas na infraestrutura para prevenir recorrências futuras.