Descrição da ferramenta: O OpenAI GPT-4o Audio Models oferece modelos de áudio avançados para desenvolvedores, incluindo conversão de fala em texto e síntese de voz, permitindo a criação de agentes de voz e transcrições com alta precisão.
Atributos:
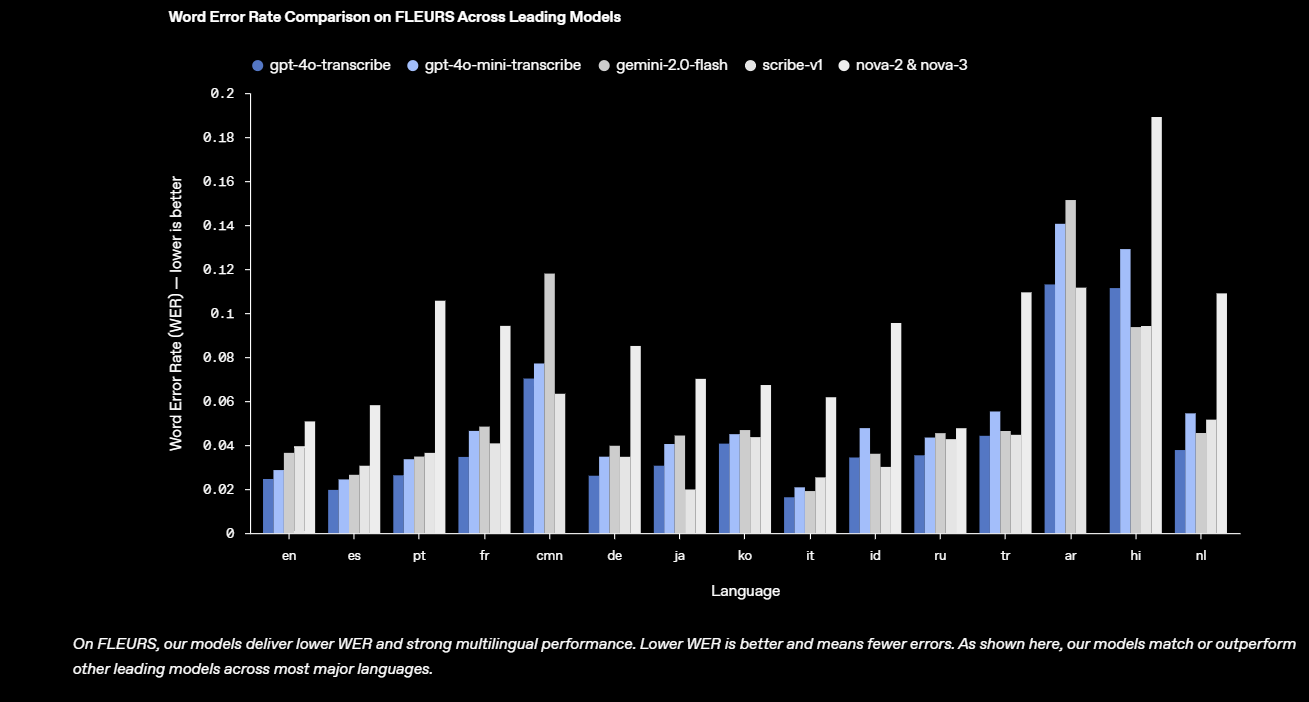
- 🎤 Precisão Aumentada: Oferece uma taxa de acerto superior na conversão de fala em texto em comparação ao modelo Whisper.
- 🔄 Sintetização Direcionável: Permite personalizar a entonação e o estilo da fala gerada, adaptando-se às necessidades do usuário.
- 🤖 Agentes de Voz: Facilita a construção de assistentes virtuais que interagem naturalmente com os usuários.
- 📝 Transcrições Eficientes: Gera transcrições precisas e rápidas, otimizando fluxos de trabalho que dependem de registros verbais.
- 🌐 Acessibilidade Ampliada: Suporta múltiplos idiomas e dialetos, tornando a tecnologia acessível a um público global.
Exemplos de uso:
- 📞 Atendimento ao Cliente: Implementação de chatbots que utilizam voz natural para interagir com clientes em tempo real.
- 🎙️ Podcasts Automatizados: Criação automática de episódios utilizando síntese vocal personalizada para narrações envolventes.
- 📚 Acessibilidade Educacional: Conversão de materiais didáticos em áudio para facilitar o aprendizado inclusivo.
- 💬 Anotações Automáticas: Transcrição instantânea durante reuniões ou aulas, promovendo eficiência na documentação.
- 🎧 Sistemas Interativos: Desenvolvimento de interfaces que respondem por meio da fala, melhorando a experiência do usuário em aplicativos.