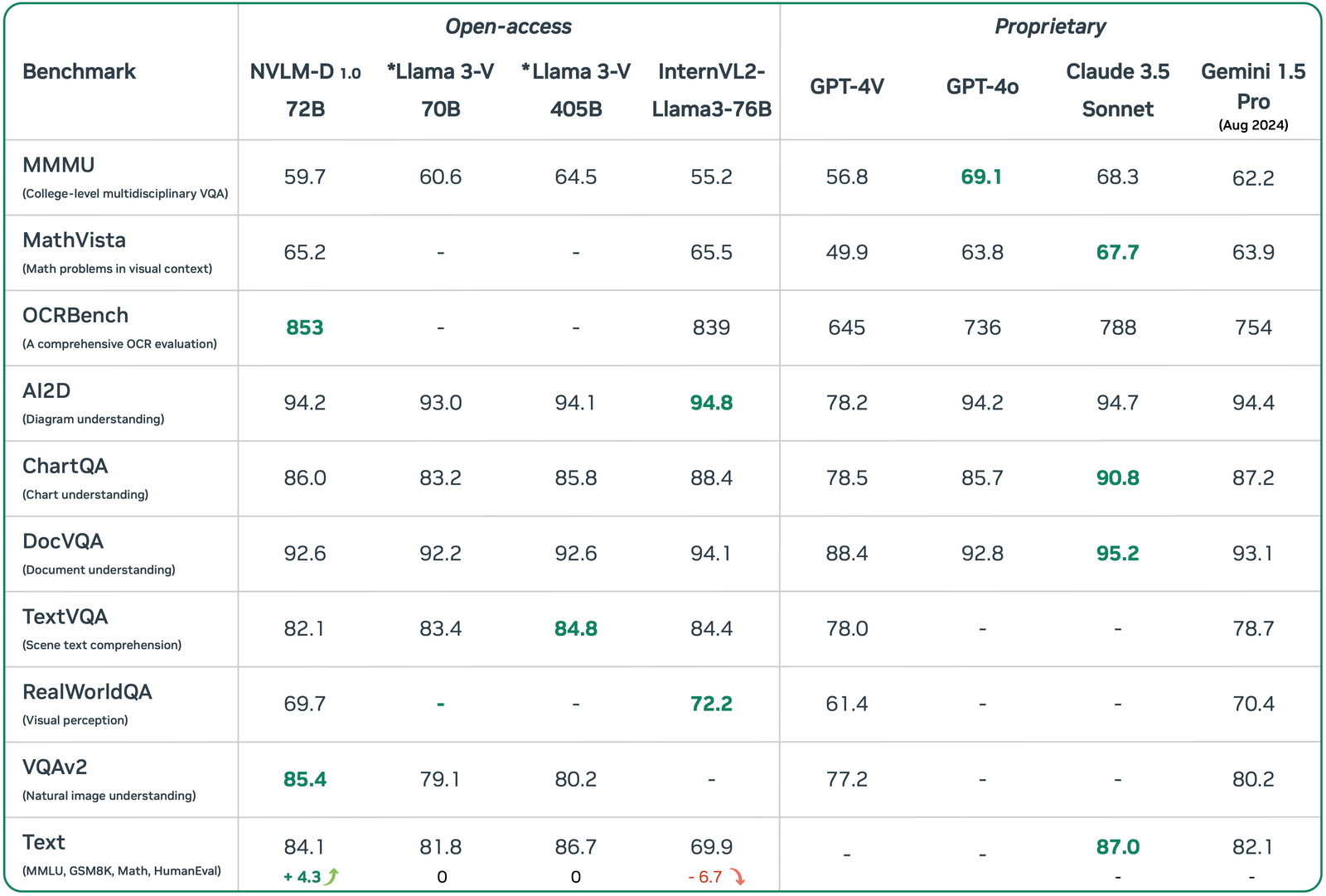
Descrição da ferramenta: Uma família de modelos de linguagem multimodal de classe fronteiriça que demonstra desempenho superior em tarefas de linguagem-visual, competindo com os melhores modelos proprietários e de código aberto disponíveis atualmente.
Atributos:
- 🧠 Capacidade Multimodal: Integração eficiente de dados textuais e visuais para uma compreensão contextual aprimorada.
- ⚡ Desempenho Superior: Resultados comparáveis ou superiores aos principais modelos do mercado, como GPT-4o.
- 🔍 Análise Contextual: Habilidade avançada em interpretar e gerar respostas baseadas em contextos complexos.
- 🌐 Acessibilidade: Disponibilidade para pesquisa e desenvolvimento por meio de plataformas abertas, como Llama 3-V 405B.
- 🔄 Adaptabilidade: Capacidade de se ajustar a diferentes domínios e tipos de dados com facilidade.
Exemplos de uso:
- 📷 Análise de Imagens: Interpretação automática de imagens para extração de informações relevantes.
- 📝 Geração de Texto Descritivo: Criação automática de descrições detalhadas a partir de conteúdos visuais.
- 🤖 Apoio à Decisão: Assistência em processos decisórios através da análise combinada de texto e imagem.
- 🎨 Criatividade Assistida: Geração colaborativa entre humanos e máquinas em projetos artísticos ou criativos.
- 📊 Análise Preditiva: Previsão baseada na combinação de dados visuais e textuais para insights estratégicos.