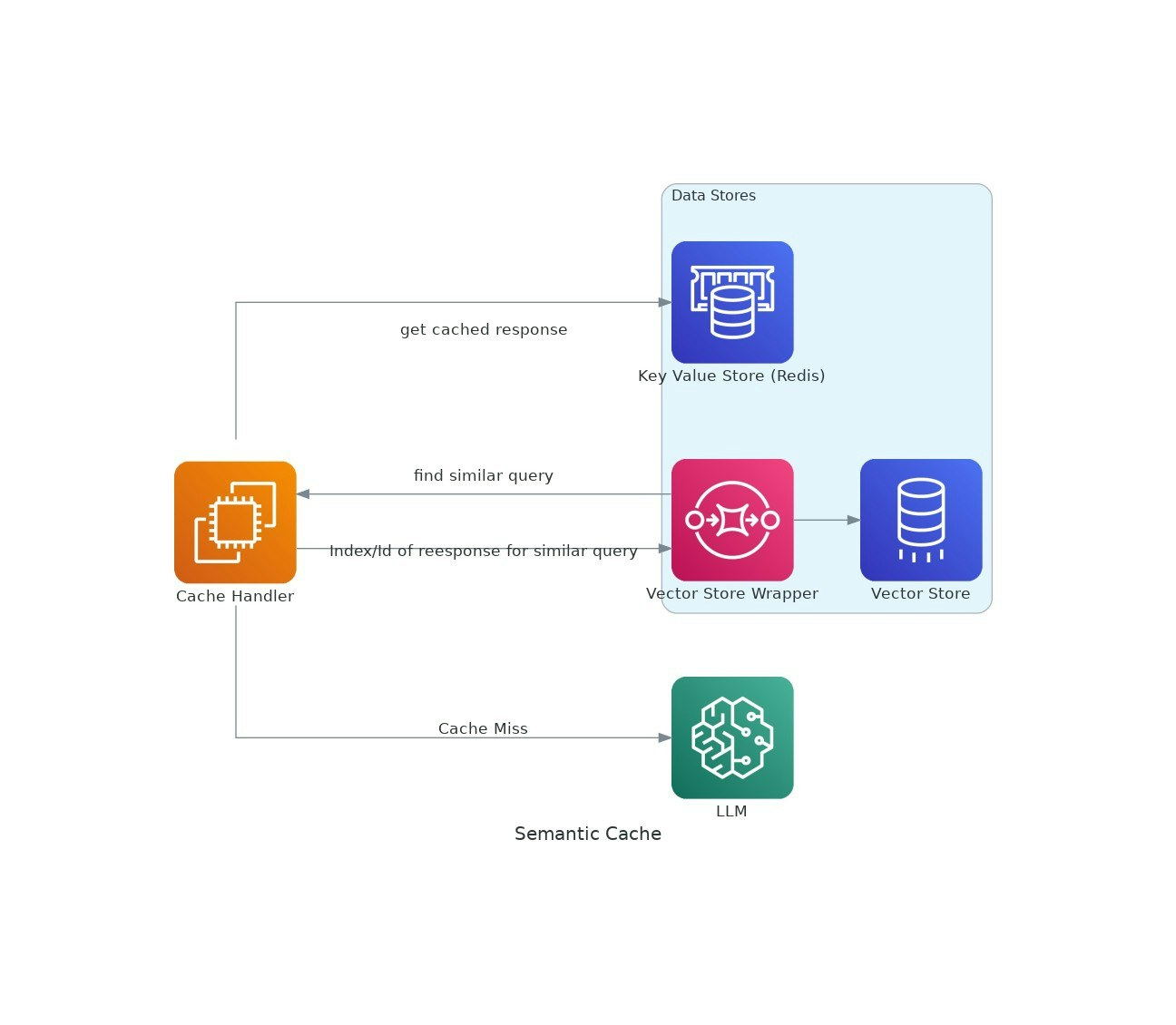
Descrição da ferramenta: O VectorCache é uma solução inovadora que otimiza o uso de grandes modelos de linguagem (LLMs) ao armazenar em cache suas respostas com base na similaridade semântica, resultando em redução de custos e latência nas aplicações de inteligência artificial.
Atributos:
- 🔄 Armazenamento em Cache: Permite a retenção de respostas anteriores, evitando chamadas repetidas aos LLMs.
- ⚡ Redução de Latência: Diminui o tempo necessário para obter respostas, melhorando a eficiência do sistema.
- 💰 Custo-Efetividade: Minimiza os gastos associados ao uso contínuo dos LLMs, tornando a operação mais econômica.
- 🔍 Análise Semântica: Utiliza técnicas avançadas para identificar e armazenar respostas com base na similaridade semântica.
- 📈 Escalabilidade: Suporta um aumento no volume de dados e consultas sem comprometer o desempenho.
Exemplos de uso:
- 🤖 Aprimoramento de Chatbots: Melhora a eficiência das interações em chatbots ao reutilizar respostas relevantes armazenadas em cache.
- 📚 Sistemas de Recomendação: Utiliza o armazenamento em cache para oferecer recomendações rápidas e precisas com base em interações anteriores.
- 📝 Análise de Sentimentos: Acelera a análise ao reter resultados semelhantes, reduzindo a necessidade de processamento repetido.
- 🌐 Pesquisa Semântica: Facilita buscas mais rápidas por informações relacionadas, utilizando dados previamente armazenados.
- 📊 Aprimoramento de Relatórios: Gera relatórios mais rapidamente ao acessar informações já processadas e armazenadas no cache.