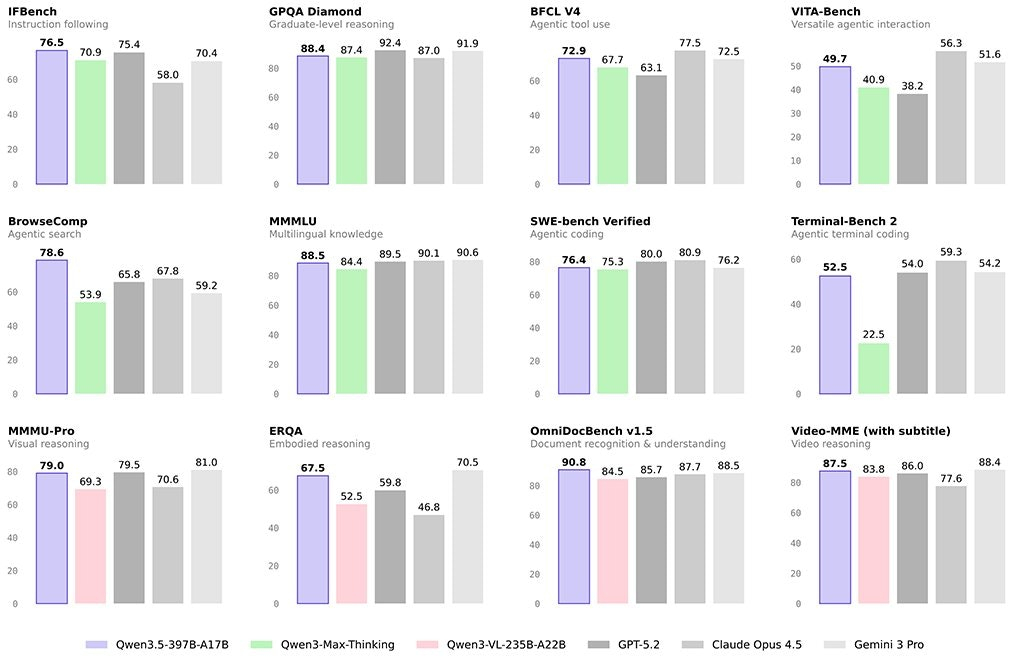
Descrição da ferramenta: Qwen3.5 é um modelo de visão-linguagem nativo, híbrido e de grande escala, projetado para tarefas de longo prazo com alta eficiência, combinando capacidade de processamento avançada com velocidade de inferência otimizada.
Atributos:
🧠 Capacidade de processamento: Possui uma arquitetura híbrida que combina atenção linear e MoE, permitindo lidar com tarefas complexas de grande escala.
⚡ Velocidade de inferência: Oferece desempenho rápido equivalente ao de modelos menores, mesmo sendo um gigante com 397 bilhões de parâmetros.
🌐 Multimodalidade: Integra informações visuais e linguísticas para compreensão avançada em tarefas multimodais.
🔧 Arquitetura híbrida: Combina diferentes técnicas (linear attention + MoE) para otimizar eficiência e capacidade.
📊 Escalabilidade: Projetado para tarefas de longo horizonte, suportando operações complexas e extensas.
Exemplos de uso:
🎯 Análise de vídeos longos: Processa conteúdo visual e textual em vídeos extensos para extração de informações relevantes.
📝 Sistemas de geração automática de relatórios: Cria relatórios detalhados a partir da análise multimodal de dados visuais e textuais.
🤖 Ações autônomas em ambientes complexos: Atua como agente inteligente em tarefas que requerem compreensão contínua do ambiente multimodal.
📚 Sistemas educacionais interativos: Fornece suporte a plataformas que combinam recursos visuais e textuais para ensino personalizado.
🔍 Análise forense digital: Auxilia na interpretação integrada de imagens, vídeos e textos em investigações digitais.